Zero-downtime PostgreSQL migrations at scale
Meta description: Advisory lock strategies, ghost table patterns, and pg_repack techniques for non-blocking PostgreSQL schema migrations on high-traffic mobile backends.
Tags: backend, architecture, api, devops, cloud
TL;DR
Schema migrations on a busy PostgreSQL database can lock tables for minutes, dropping thousands of mobile API requests. Advisory locks coordinate migration runners safely, the ghost table pattern avoids ACCESS EXCLUSIVE locks on writes, pg_repack reclaims bloat without downtime, and CREATE INDEX CONCURRENTLY has failure modes most teams never test for. This is the playbook I use for mobile backends handling 10k+ requests per second.
The cost of two seconds
On a mobile API backend serving 12,000 req/s, a two-second ACCESS EXCLUSIVE lock means roughly 24,000 failed or queued requests. Users see spinners, retry storms hit your load balancer, and your on-call engineer’s heart rate spikes. I’ve lived it. HealthyDesk reminded me to take a break right before I got the page, which was ironic timing.
Standard ALTER TABLE ... ADD COLUMN with a DEFAULT in PostgreSQL <11 rewrites the entire table. Even on PostgreSQL 14+, some operations still acquire the heaviest lock. The patterns below eliminate that risk.
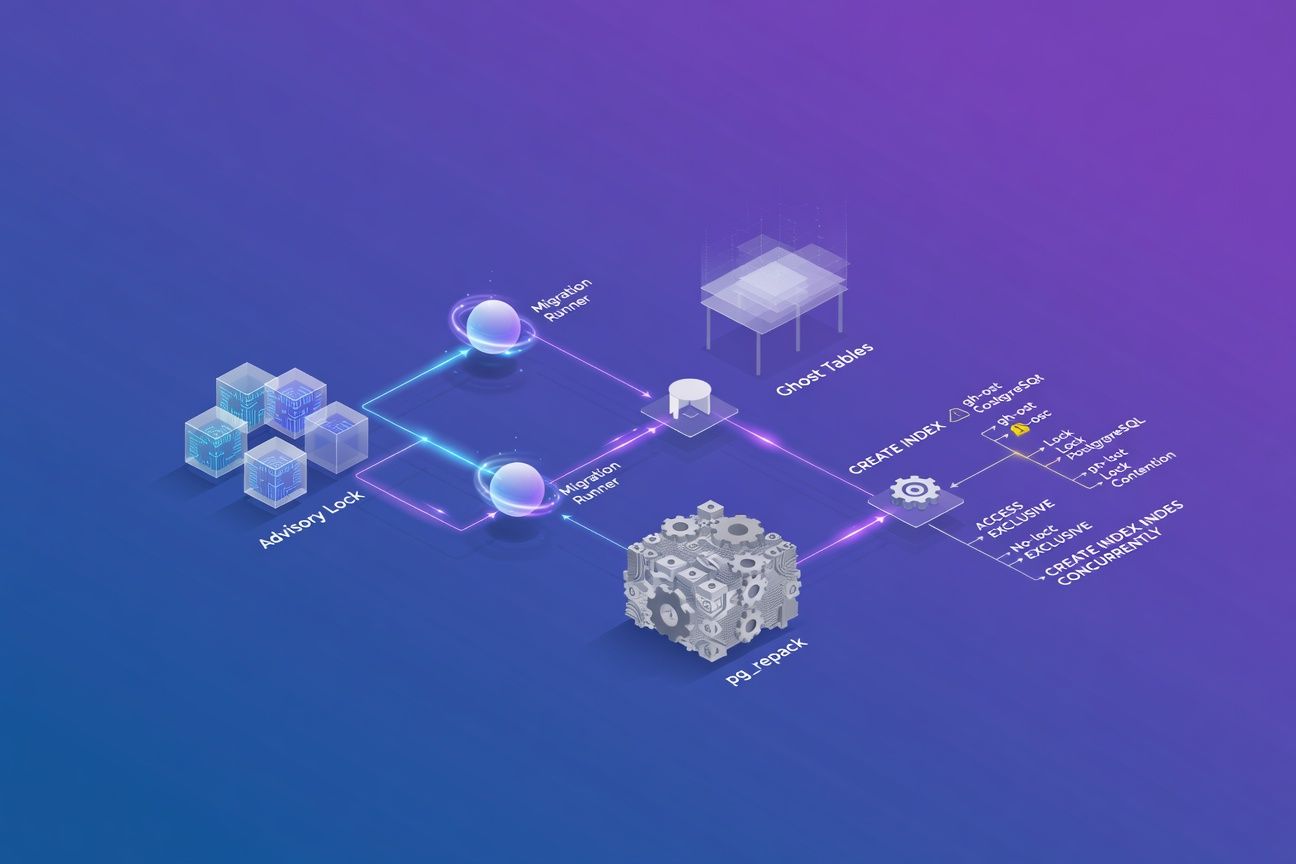
Advisory locks: coordinating migration runners
When you run multiple application instances (Kubernetes pods, ECS tasks), more than one can attempt the same migration simultaneously. Flyway and Liquibase handle this internally, but custom runners or scripts need explicit coordination.
-- Acquire an advisory lock before migrating
SELECT pg_advisory_lock(hashtext('migrations_lock'));
-- Run migration steps...
-- Release
SELECT pg_advisory_unlock(hashtext('migrations_lock'));A few rules that matter:
- Use session-level locks (
pg_advisory_lock), not transaction-level. If your migration spans multiple transactions, transaction-level locks release too early. - Set a
lock_timeouton the session:SET lock_timeout = '5s';. Fail fast rather than queue behind a long-running query. - Always release explicitly. PostgreSQL cleans up if the session crashes, but relying on that is sloppy.
The ghost table pattern
This is the technique behind GitHub’s gh-ost and Zendesk’s pg-osc, adapted from MySQL tooling to PostgreSQL.
| Step | Action | Lock required |
|---|---|---|
| 1 | Create a “ghost” table with the new schema | None |
| 2 | Install triggers on the original to replicate DML to the ghost | SHARE ROW EXCLUSIVE (brief) |
| 3 | Backfill existing rows in batches | None |
| 4 | Swap table names via ALTER TABLE ... RENAME | ACCESS EXCLUSIVE (milliseconds) |
| 5 | Drop old table | None |
The key insight: step 4 is the only moment you hold the dangerous lock, and it completes in single-digit milliseconds because it’s a metadata-only operation.
-- Step 4: the atomic swap
BEGIN;
ALTER TABLE orders RENAME TO orders_old;
ALTER TABLE orders_ghost RENAME TO orders;
COMMIT;The trigger-based replication in step 2 is where teams get bitten. You must handle INSERT, UPDATE, and DELETE, and your trigger must be idempotent to survive the overlap between backfill and live traffic. I’ve seen this go wrong when someone forgets the DELETE case and ends up with ghost rows that should have been purged.
pg_repack: bloat reclamation without downtime
After heavy UPDATE/DELETE workloads, table bloat inflates storage and destroys sequential scan performance. VACUUM FULL fixes bloat but takes an ACCESS EXCLUSIVE lock for the entire duration. pg_repack does the same job without it.
| Tool | Lock type | Duration | Online? |
|---|---|---|---|
VACUUM FULL | ACCESS EXCLUSIVE | Minutes to hours | No |
pg_repack | ACCESS EXCLUSIVE | Milliseconds (swap only) | Yes |
CLUSTER | ACCESS EXCLUSIVE | Minutes to hours | No |
pg_repack --table orders --no-superuser-check -d mydbInternally it’s the same ghost table idea: build a new copy, replay changes via triggers, swap. One caveat — pg_repack requires free disk space equal to the table size plus indexes. Monitor pg_stat_user_tables.n_dead_tup and schedule runs before bloat exceeds 30%.
CREATE INDEX CONCURRENTLY: the silent failure
You probably know to use CONCURRENTLY to avoid locking writes. You might not know it can silently produce an invalid index.
CREATE INDEX CONCURRENTLY idx_orders_user ON orders(user_id);
-- Always verify afterward
SELECT indexrelid::regclass, indisvalid
FROM pg_index
WHERE indexrelid = 'idx_orders_user'::regclass;If indisvalid is false, the index exists but the planner ignores it. You have to DROP INDEX CONCURRENTLY and retry. The other common mistake: wrapping CREATE INDEX CONCURRENTLY inside a transaction block. PostgreSQL explicitly disallows this and the command fails immediately. Your migration tool must run it outside a transaction.
The migration playbook
For every schema change on our mobile backend, we follow this checklist:
- Classify the operation — metadata-only (safe) or table rewrite (dangerous)
- Test on a production-size replica — measure lock duration and WAL generation
- Deploy with advisory locks to coordinate across pods
- Use ghost tables for destructive changes like column type changes or
NOT NULLadditions on large tables - Validate indexes post-creation with an automated check in CI
- Schedule pg_repack weekly for high-churn tables
What I’d actually do first
Set lock_timeout on every migration session. A 5-second timeout prevents cascading lock queues that turn a minor migration into a full outage. This single setting has saved me from more pages than any other config change.
Never trust CREATE INDEX CONCURRENTLY without validation. Add an automated post-migration check for indisvalid = false in your CI pipeline. Silent index failures cause slow queries that surface days later, and they’re miserable to debug because nobody thinks to check the index itself.
Adopt the ghost table pattern for any table over 1GB. The upfront complexity of triggers and backfill pays for itself the first time you skip a multi-second lock during peak traffic. Tools like pg-osc automate most of it.
Schema migrations deserve the same rigor as your API design. Get them wrong and your users feel it immediately, even if they never know why.